
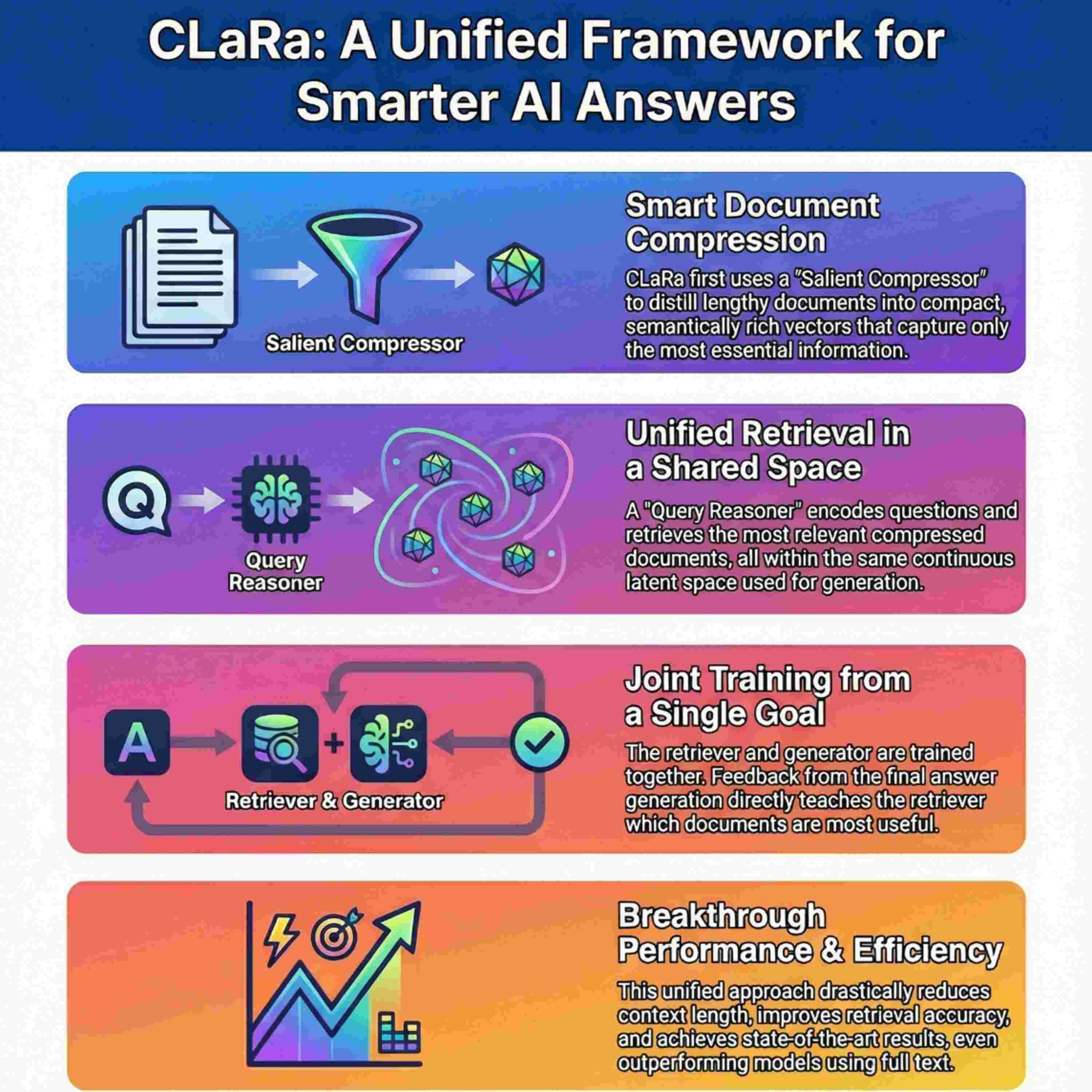
This paper discusses how Retrieval-Augmented Generation (RAG) framework can be designed to overcome the structural issues of separate retrieval and generation modules. The proposed framework, CLaRa, achieves this by employing a **shared latent space** where documents are compressed into concise, continuous memory-token representations, addressing the architectural mismatch and efficiency problems of traditional RAG. Key to CLaRa is its **joint optimization** mechanism, which uses the Next-Token Prediction loss from the generator to provide a weak supervision signal, aligning the retriever with the downstream task objective without requiring explicit relevance labels. The framework uses a diverse dataset of **Simple QA, Complex QA, and Paraphrase pairs** for pretraining, and empirical results show that CLaRa, particularly when initialized from pretraining, achieves **state-of-the-art retrieval performance** that rivals or surpasses fully supervised baselines on various question-answering tasks. Furthermore, analyses confirm that the compressed representations successfully **preserve semantic content** while substantially reducing the context length, significantly improving overall system efficiency.