
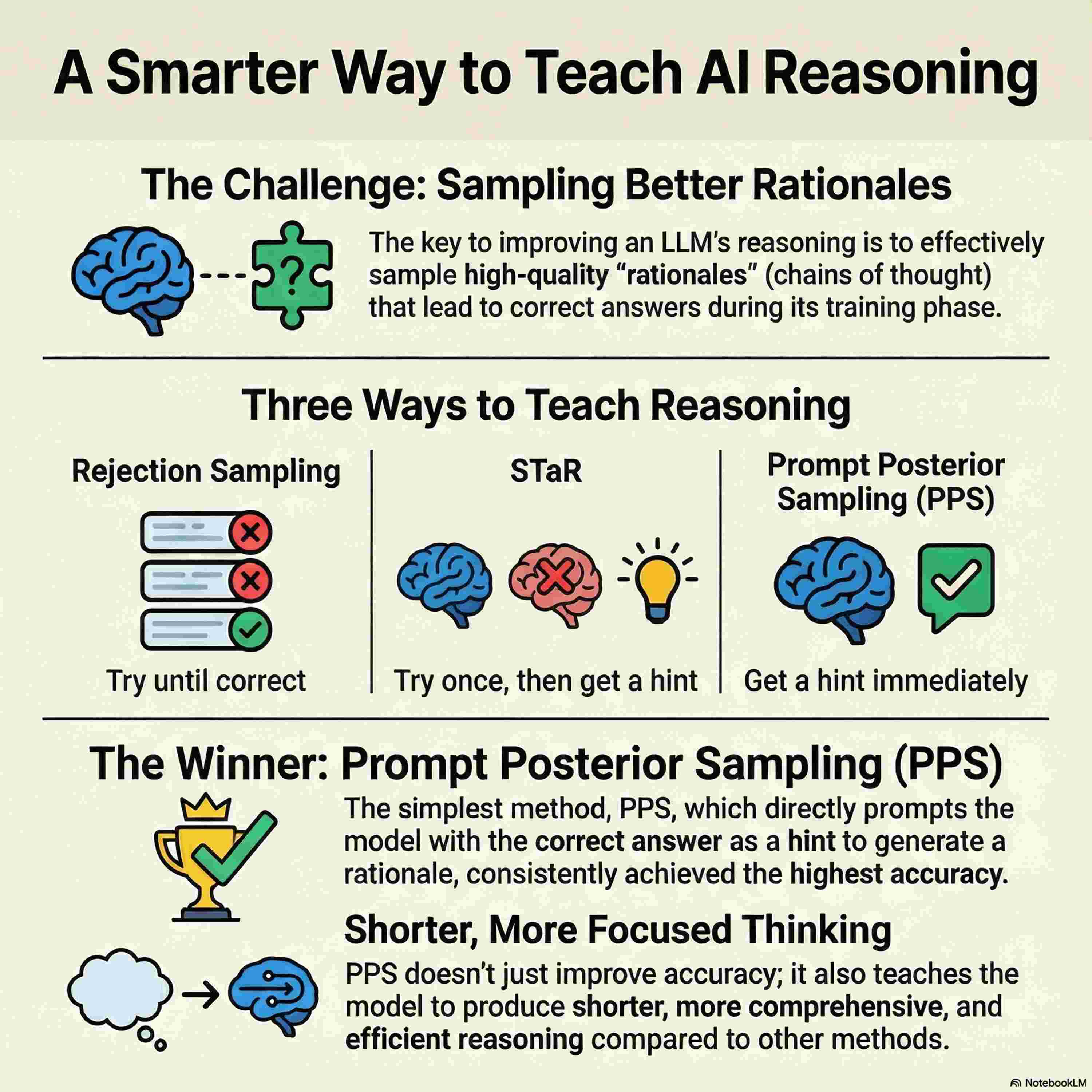
This research formalizes the process of reasoning in large language models as a latent variable model, utilizing the expectation-maximization (EM) algorithm to improve performance. The authors demonstrate that training a model to generate intermediate rationales before answering is mathematically equivalent to reward-weighted fine-tuning using binary correctness as a signal. A central focus of the study is the sampling distribution used to create these rationales, comparing methods like rejection sampling and the self-taught reasoner (STaR). The paper introduces prompt posterior sampling (PPS), a technique that conditions the model on the correct answer during training to generate more effective reasoning traces. Experiments across multiple benchmarks show that PPS consistently outperforms existing methods by producing more concise and accurate rationales. Ultimately, the work highlights that high-quality rationale generation is just as critical to model improvement as the underlying optimization algorithms.